How we over-engineered our data pipeline...
How we over-engineered our data pipeline... and why it was a mistake.
— About 8 minutes of reading
— Published on November 29, 2024
— Updated on November 29, 2024
Tech
Data Pipeline
Data Engineering

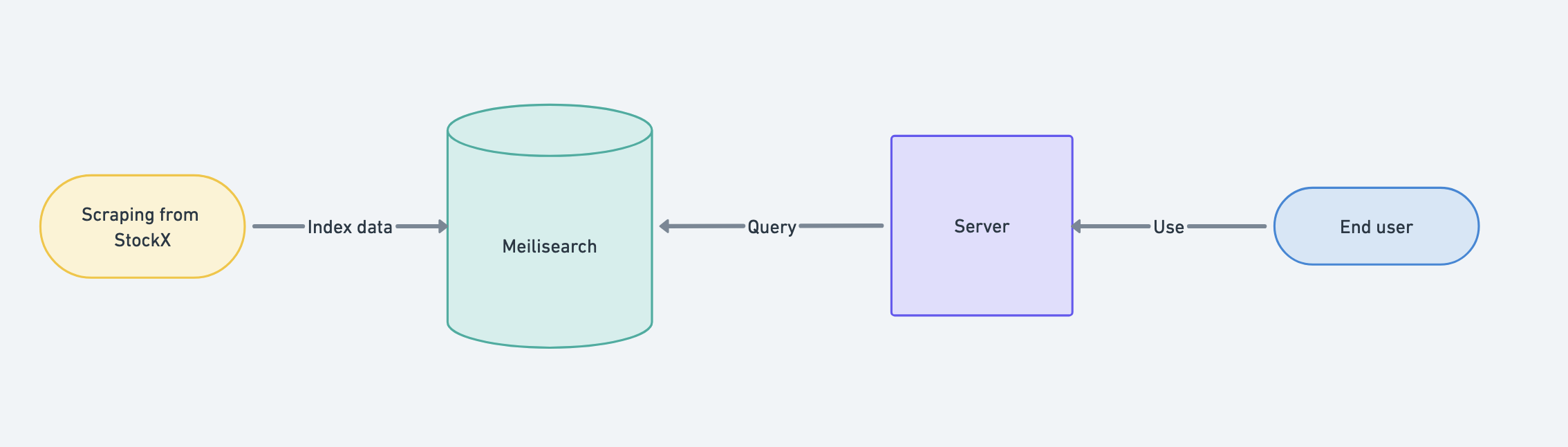
When we launched SneakersAPI.dev, our goal was simplicity. It was a proof of concept - a quick experiment to gauge interest in our product. At that stage, our setup was straightforward: a data scraper, a modest server, and Meilisearch for full-text search. We ran the scraper daily, updated the Meilisearch index, and that was it.
But beneath this simplicity lay a ticking time bomb of issues:
- Meilisearch is not a database. If we wanted to aggregate or expand our solution, a migration was inevitable.
- Vertical scaling only. Meilisearch couldn’t handle sharding or distributed clusters, limiting its scalability.
- Low-cost server. Our PoC server was a humble $5 instance from Hetzner with just 1GB of RAM. Attempting full-text search with such limited resources was a recipe for disaster. The API would timeout regularly during indexing.
The initial setup lasted for about eight months, without any plans for scaling it into the robust solution that SneakersAPI.dev would eventually become. I had almost forgotten about this small side-project, but then one day, I checked the RapidAPI dashboard and noticed that multiple users were accessing the API. This resulted in approximately 50,000 daily requests.
This was a wake-up call, as the data quality was subpar, the server was located in Europe while most users were in the USA (leading to high latency), and we were the only free provider for this type of data. Even today, there is no other free API for sneakers and fashion data, except ours.
It was clear that it was time to build something more substantial. The old website was a mess, hosted on a personal domain, and the API was only available on RapidAPI.
How to make a bad data-pipeline
I turned to ClickHouse, an OLAP database I had been working with professionally for two years. ClickHouse is designed for ingesting and aggregating vast amounts of data, from millions to billions of rows.
I chose ClickHouse because it’s fast, open-source, easy to self-host, and comes with hundreds of functions for a wide range of tasks. Additionally, its insert-trigger-based materialized views seemed perfect for building a data pipeline without additional tools.
However, while ClickHouse is excellent for aggregating and reading large-scale data, it proved to be overkill for reading individual rows. The new API I had built was responding in around 900ms for a simple WHERE id = [id] statement, which was unacceptable. To address this issue, I implemented a new plan:
- Kept ClickHouse for data ingestion and aggregation.
- Replicated the aggregated data to PostgreSQL and indexed it correctly.
- Also replicated the data to Meilisearch, which consistently responded in less than 50ms.
This approach allowed me to leverage ClickHouse’s strengths in data ingestion and aggregation, while using PostgreSQL and Meilisearch for efficient individual row lookups.
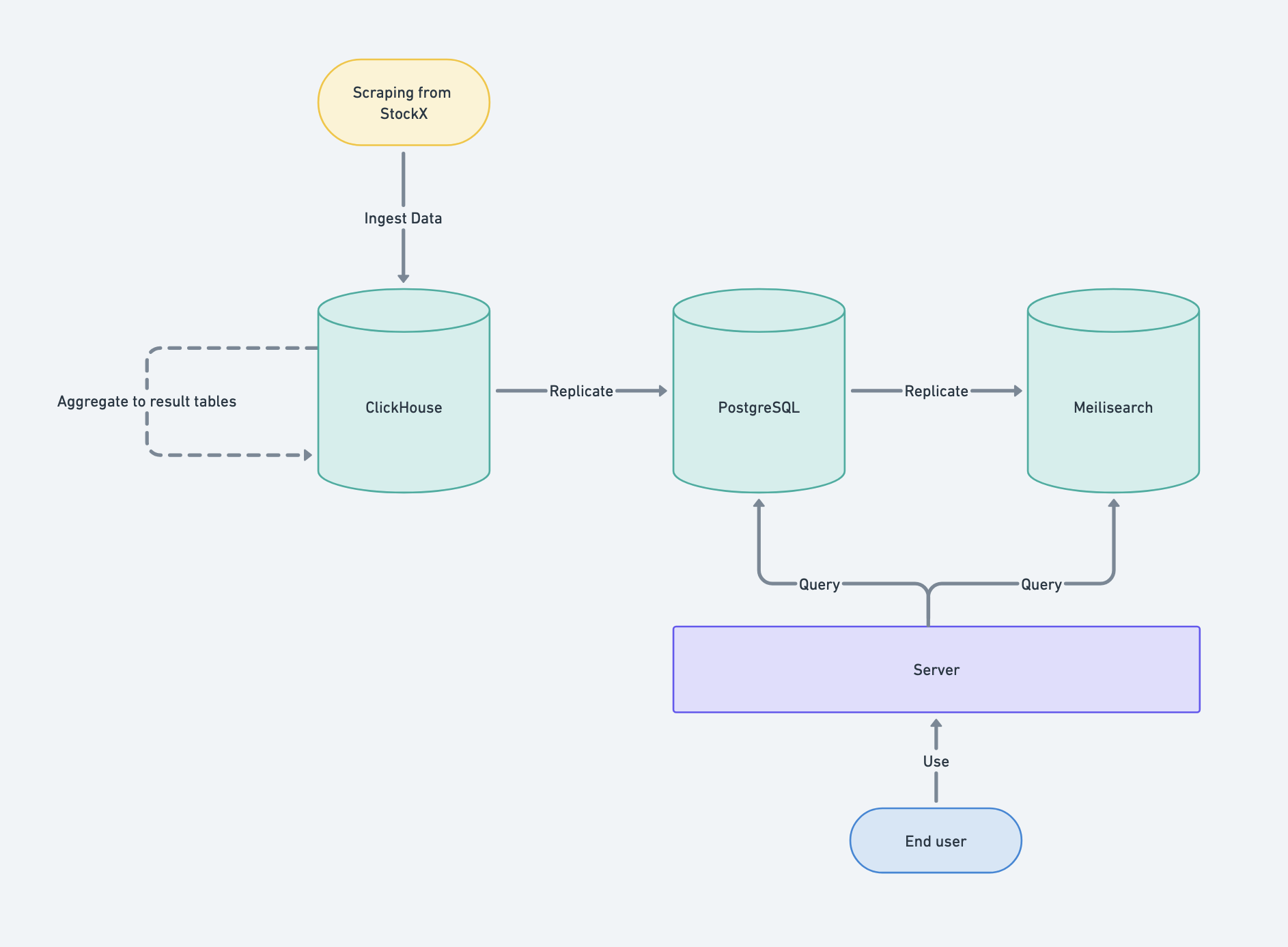
The decision to use ClickHouse, despite it not fitting the rest of the pipeline, has proven to be a poor choice. This has resulted in the need to maintain three separate services, including two costly ones (ClickHouse and Meilisearch, both resource-intensive) for an API that receives less than 50,000 daily requests.
Additionally, the maintenance of scripts to copy and replicate data from one source to another has become increasingly burdensome as the data volume has grown. Meilisearch, in particular, has been causing significant issues, with its indexing process consuming up to 400% of the server’s CPU twice a day.
Furthermore, the lack of orchestration and error-handling mechanisms has led to a significant data loss incident, where 14 days’ worth of data was lost without any alerting or recovery protocol in place.
In summary, this setup was inefficient, costly, and prone to failures, highlighting the need for a more streamlined and robust data pipeline architecture.
In late October, I started collecting user feedback. Many users requested improvements to data quality, such as missing images, incorrect retail prices, and wrong release dates.
As I mentioned earlier, our data pipeline consists of SQL migration scripts using the Goose tool. While I still use Goose in the new pipeline, it’s not an ideal tool for building data pipelines, as it lacks visibility into the pipeline’s operations.
Additionally, the server hosting the pipeline was experiencing difficulties. I had to frequently switch server providers to find the best balance of RAM and cost, which was a hassle to manage.
Rewriting from scratch
Initially, I tried to use only ClickHouse. The pipeline was working, but it was difficult to maintain due to the need for migration scripts and the use of many ClickHouse-specific functions. This made it challenging to switch to another database. I then explored alternative solutions, such as data-skipping indexes and the MaterializedPostgres engine, to automatically replicate the data without the need for scripts.
However, these approaches were not satisfactory:
- Data-skipping indexes were not efficient for our use-case.
- The MaterializedPostgres engine simply did not work for us.
I explored a few potential solutions, but they all had significant drawbacks:
- Neo4J: I initially thought a graph database would be a good fit for SneakersAPI.dev, as the goal is to link product data from various sources. However, I found the data ingestion process to be incredibly slow, and it lacked the necessary capabilities for performing aggregations. This turned out to be a poor choice.
- SurrealDB: This emerging solution caught my interest, as it combines traditional database, graph database, and key-value functionalities in a single platform. While I appreciate the effort and the developer experience (including a quick start and a desktop GUI app), the current implementation is quite slow and lacks essential features, such as the ability to extract captures from regular expressions.
The data ingestion and performance issues, as well as the lack of critical functionalities, led me to conclude that these were not viable solutions for the project. I had spent too much time experimenting with new solutions, so it was time to move on and provide a true solution. Fortunately, I then came across some helpful resources.
- dbt (Data Build Tool) is a powerful tool that allows you to build data pipelines using Jinja templating with support for PostgreSQL.
- “PostgreSQL full-text search is better than…”, a blog article highlights how PostgreSQL’s full-text search capabilities can be a viable and often preferable solution compared to other search engines like Elastic or Meilisearch. The article is supported by a related discussion on Reddit, which echoes the same sentiment.
- TimescaleDB, an extension for PostgreSQL that provides better support for working with time-series data, which is also something we work with.
I combined three elements into one, and that’s how SneakersAPI v2 came to be. While it may sound straightforward, but working with dbt is a remarkably simple yet powerful tool, and it’s been a pleasure to work with.

Image shamefully stolen from Seattle Data Guy on YouTube.
A look at the new pipeline
Here is a look at the data pipeline:
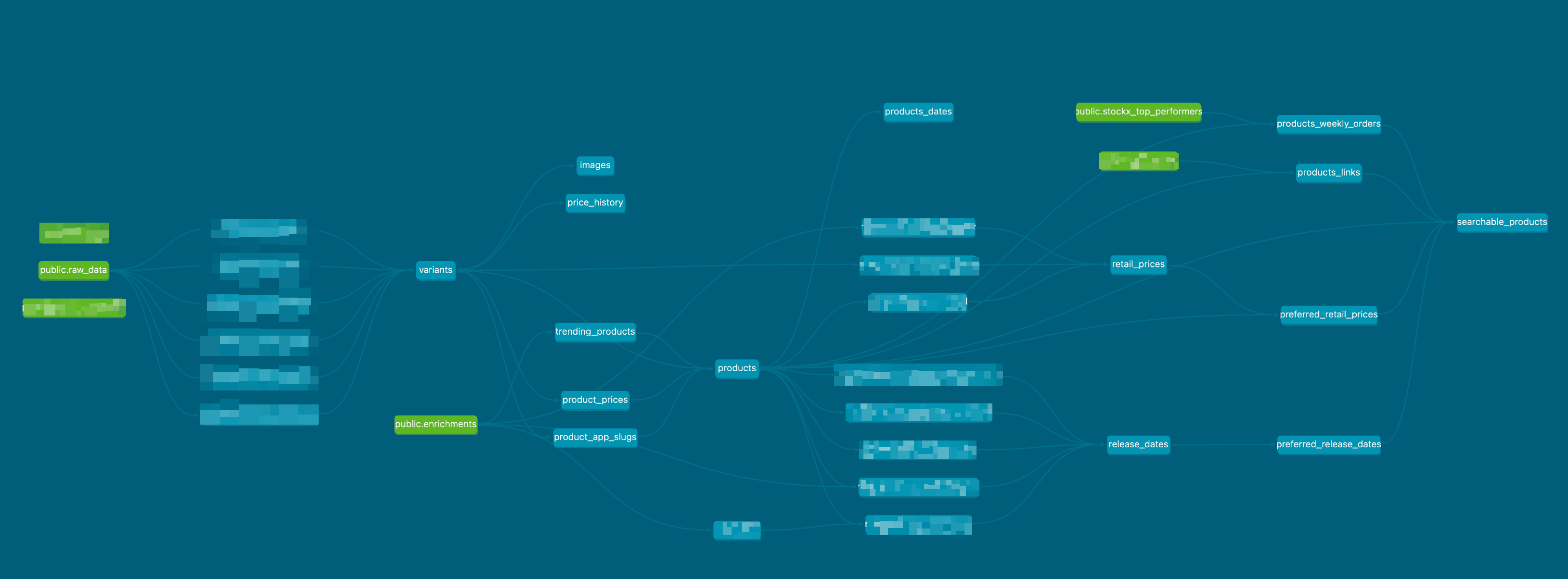
dbt allows you to generate a dependency graph using the dbt docs generate and dbt docs serve commands. You can also document each SQL model, which we haven’t done yet.
The schema.yml file is used to specify which SQL models should be run. You can also define pre/post-hooks to execute specific SQL commands, which is useful for managing TimescaleDB hypertables and partitioning. dbt also supports out-of-the-box index creation, which we use to improve the performance of user queries.
Regarding the ingestion pipeline, it looks like the following:
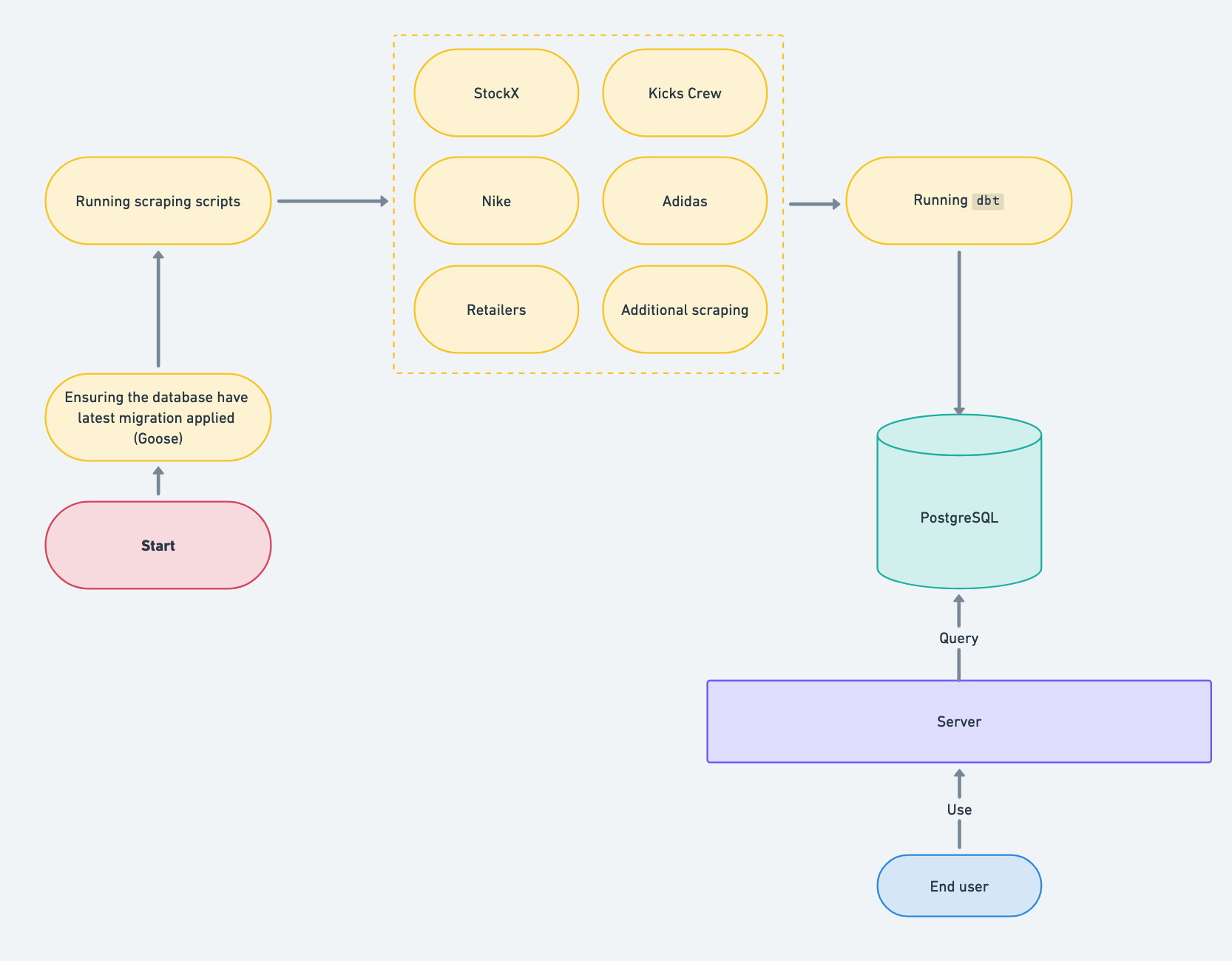
Currently, we use simple cron jobs with an external monitoring service to receive alerts in case of issues. Our next goal is to migrate to a solution like Airflow. Our scripts are written in Go, as I’m proficient with the language. It’s also straightforward to containerize the scripts using Docker.
Approximately 90% of our pipeline runs in Docker containers, which are built using GitHub Actions CI/CD.
Conclusion
The key message is: don’t over-engineer. It’s acceptable to have a dbt pipeline that takes 30 minutes to run, even if ClickHouse could complete the same task in just 2 minutes. The focus should be on delivering value efficiently, rather than optimizing for the fastest possible runtime. Optimizing solely for speed can lead to a complex and un-optimized pipeline.
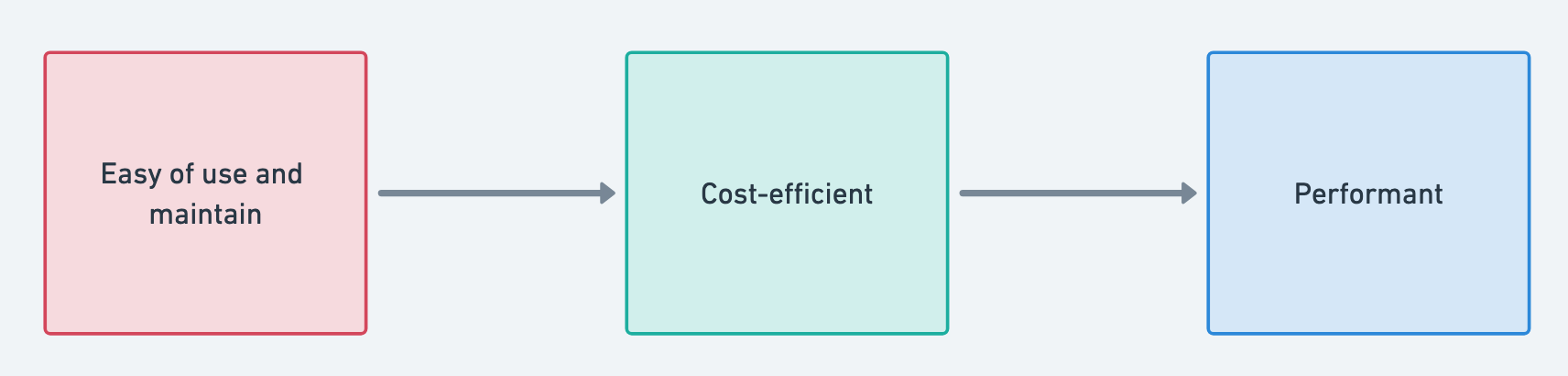
This image shows the priorities we have established:
- Ease of Maintenance: As data quality demands increase, we need to be able to easily maintain and update our data pipeline. Using
dbtand a single database solves this. - Cost-Efficiency: Our business is niche, and while we’re proud to have our first paying subscribers, we can’t afford a $900/month bare-metal server.
- Performance: While timely data ingestion and access is important, it’s not critical if it takes 20 minutes or an hour, as long as the pipeline is reliable and provides satisfactory results.
Data engineering is a vast field with numerous online solutions for building pipelines, ingesting data, and transforming it. The most effective approach for us was to conduct thorough research and develop a plan that prioritized our specific needs.
Thank you for reading. We’re constantly working to improve our data. We’ve opened a Discord server to discuss with the community. Feel free to join and share what you’ve built using our API!